ARTÍCULO DE INVESTIGACIÓN
• VÍNCULOS-ESPE (2023) VOL.8, No.1:41-60
DOI: https://doi.org/10.24133/vinculosespe.v8i1.3114
Analysing Vocabulary in Human Graded L2 Scripts
Through Automatic Lexical Analysers
Análisis del vocabulario de alfabetos L2.
A través de analizadores léxicos automáticos
JOSÉ LEMA ALARCÓN
![]()
Universidad de las Fuerzas Armadas - ESPE
Av. General Rumiñahui y Ambato, Sangolquí-Ecuador
jslema@espe.edu.ec
ABSTRACT
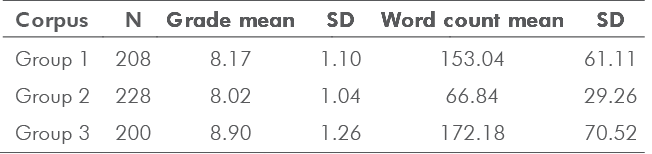
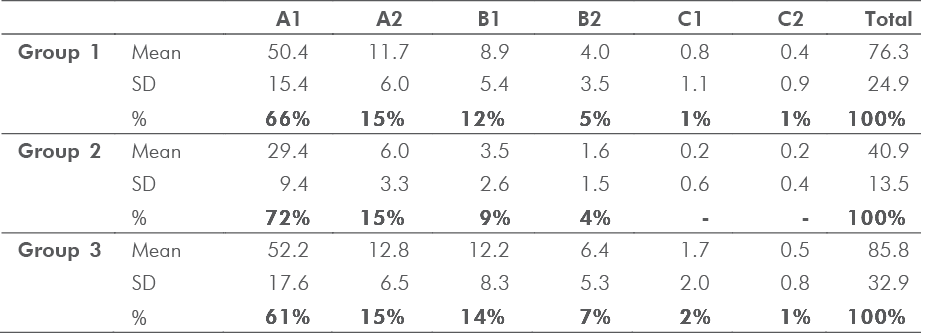
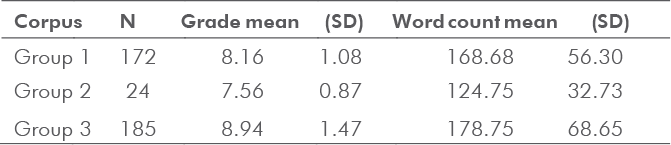
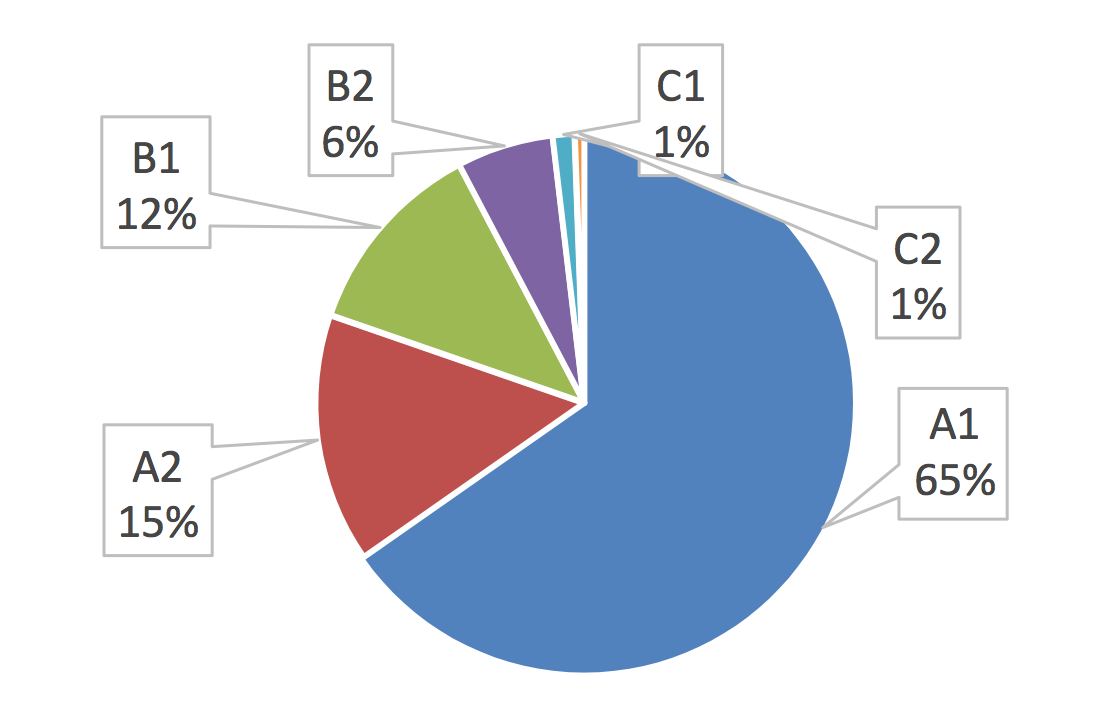
In grading second language (L2) scripts, teachers take approximate measures regarding lexical choices that may suggest the overall quality of the texts. This study compared various measures of lexical proficiency in scripts written by English language students. The corpus was analyzed to determine the correlation between teacher judgments and lexical items in L2 written assignments. Using the Text Inspector online tool, the study first attempted to delimit the lexical items corresponding to levels (e.g., A1/2, B1/2, and C1/2) of the Common European Framework of Reference for Languages (CEFR). In addition to verifying vocabulary levels, the study also used the Tool for the Automatic Analysis of Lexical
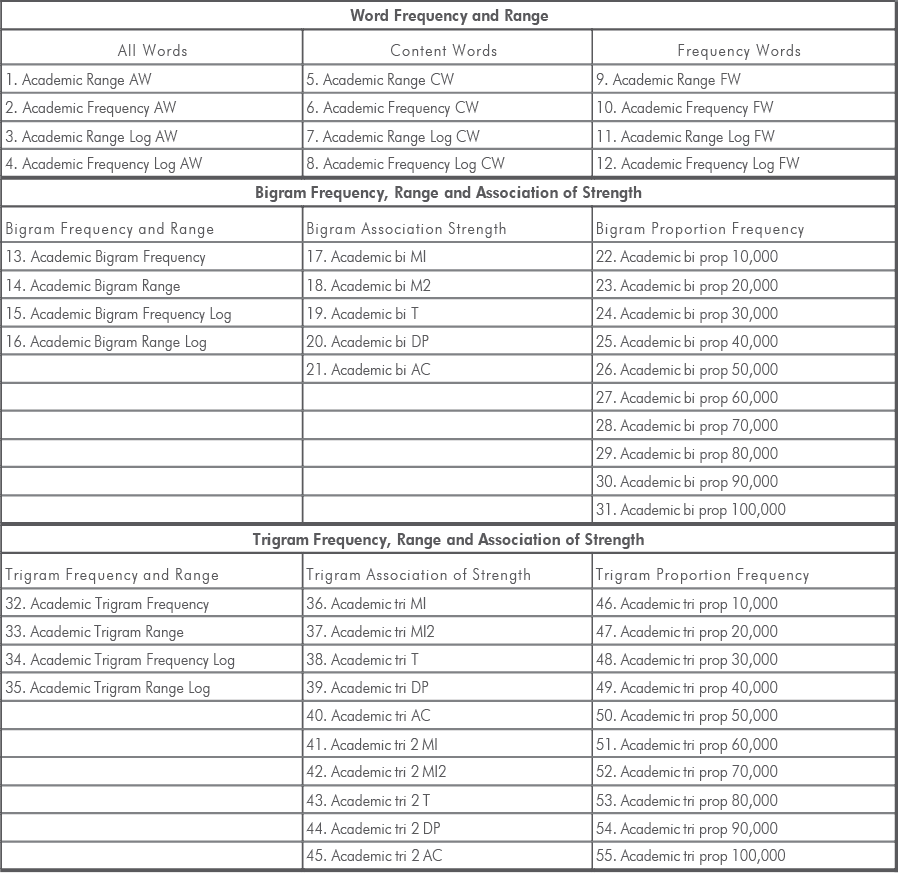
Sophistication (TAALES) to analyze advanced words and phrases used in each script. Using the Text Inspector tool, the first part of the study demonstrated that the assigned grades for each script correlated with the CEFR word lists. Similarly, the grades and L2 scripts were correlated with twenty-two indices of lexical sophistication (i.e., academic word frequency, range and N-gram proportion frequency).
Keywords: Lexical sophistication, CEFR vocabulary levels, Text Inspector, TAALES, English Vocabulary Profile EVP, vocabulary, writing proficiency, grading.
Recibido: 2022-10-15
Aceptado: 2022-12-15
41